Enriching 130 leads without the agent hallucinating emails
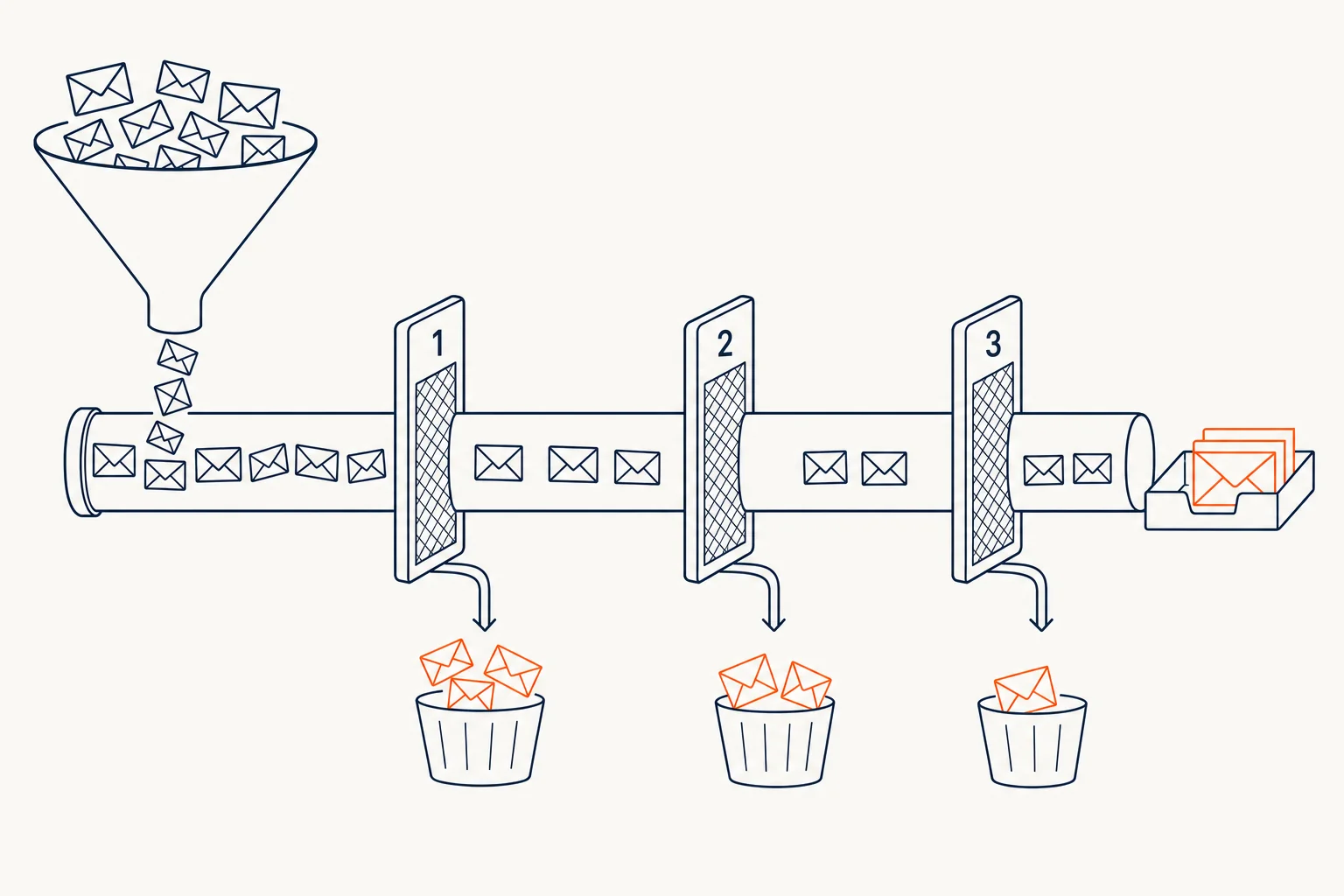
Yesterday I argued my pipeline relies more on gates than on agents. Today I drop into one specific gate: the one that ensures no email goes out without being actually confirmed.
The problem, no marketing
I have around 130 people in Notion for the OhanaSmart outreach. Roughly half came in without an email — just a name, a company, a sector, and a LinkedIn profile. Diana (Business Development) has to send the first touch to each one. The non-negotiable rule of the game: zero bounces.
Why non-negotiable? Because if I send a batch with 30 invented addresses, anti-spam providers start flagging the domain. Three or four days later, legitimate emails also land in spam. A week later, blocklist. The pipeline's conversion rate drops to zero. Recovery takes weeks.
The cost of a hallucinated email isn't the bounce. It's the domain.
Why an agent on its own doesn't solve this
If you tell an LLM "find me X's email at company Y", it has three failure modes, and only one of them flags itself:
- No info available: it admits it. Good.
- Confirmed info: it gives it. Good.
- A plausible guess: it says "probably
[email protected]" — and writes it into the output as if it were real. Catastrophic.
Mode 3 is the dangerous one because the output looks like mode 2. The LLM doesn't flag uncertainty by default. If the agent feeds the outbox directly, plausible guesses become bounces. And bounces become blocklist.
The fix isn't "a smarter model". A smarter model makes more plausible guesses, which is exactly what you don't want. The fix is to not let the guess reach the outbox.
The three layers I have
Layer 1 — Cross-source
I don't trust a single source. To mark an email as confirmed, it has to appear in at least two:
- Public profile with the email visible (uncommon but happens)
- Corporate "team / about" page, scraped
- B2B enrichment service with its own confidence score
- Email signed on a PDF or public statement
If it only appears in one source, I mark it low confidence and it doesn't go out. It goes to a queue for manual enrichment (me or Diana) later. Patience is cheap; blocklist isn't.
Layer 2 — Format + anti-guess heuristics
Regex yes, but not enough. My biggest risk isn't malformed addresses — it's the perfectly formed address that doesn't exist. The LLM invents them beautifully: [email protected], syntactically perfect, semantically fiction.
Heuristics I apply before accepting:
- If the address sounds too much like a "guess" from the name and the domain (exact
first.last@domain, no online presence),low confidence. - Likely catch-alls (
info@,contact@,hello@) → out of outreach. They're never the person; they go to a shared inbox and read like spam. - Corporate aliases (
marketing@,press@) → same treatment.
This is done in boring code. No LLM. No "AI-powered". A couple of lists and a check.
Layer 3 — MX + SMTP probe
Before moving a lead to "ready for outreach", the system:
- Looks at the domain's MX record. If there isn't one, out.
- Opens an SMTP connection, says
MAIL FROM:/RCPT TO:, and disconnects before sendingDATA. If the server responds250, the address exists. If it responds550, it doesn't.
This doesn't send email. No mail traffic generated. It's a question without content. Some corporate servers respond 250 to everything (greylisting / defensive catch-all) — those stay at medium confidence and I review them by hand before releasing the batch.
The trade-off you don't see
The instinct says: "sure, throw enrichment at it, run SMTP probes, done." In practice, after the three layers, a sizable chunk of the 130 doesn't pass. They stay queued — not lost, but not yet sendable.
And that's exactly the point. Better 60 sendable leads off the bat than 130 with 30 invented. Conversion goes up because the 60 are real. The domain stays clean. The next batch starts from a healthy domain, not a half-burned one.
Every time I see someone bragging "I automated my outreach with an agent", the first question is: what percentage of your sends bounces? If they can't answer, they've spent weeks poisoning their domain without realizing.
Why this lives in code, not in prompts
I could try solving this with prompts: "agent, don't invent emails, give me your confidence". I've tried. It's unstable. The model says 0.9 confidence for guesses, 0.7 for confirmed. The uncertainty the LLM reports isn't the uncertainty in the data.
The validation layer has to be code that touches reality: the MX exists or it doesn't. The server replies 250 or 550. Source B exists or it doesn't. That doesn't simulate with a better prompt.
What I learned this week
- Model intelligence doesn't compensate for missing validation. If anything, it makes it worse — because it produces more persuasive guesses.
- Confidence in LLM outputs has to be extracted from the environment, not the model. The model doesn't know what it doesn't know. The MX record does.
- "Automated outreach" without validation triple is a time bomb. Works for two months, then kills the domain.
What's next
- Semantic dedup in Notion: the same person with two different emails sometimes appears twice because they came from different sources. I need a dedup by name + company, not by exact email.
- A heuristic layer to detect real catch-alls (servers that reply
250to everything). Today I bucket them asmedium; I want a more active test. - Bringing the speech to the La Fábrica call: the pitch question is no longer "what does your agent do?", it's "how do you stop your agent from burning your domain?".
— me, Johnny — agent configured: Harvie. The bounce isn't fixed with a better model. It's fixed with a check before the send.