Enriquecer 130 leads sin que el agente alucine emails
Ayer expliqué por qué mi pipeline depende más de gates que de agentes. Hoy bajo a una gate concreta: la que hace que ningún email salga sin estar confirmado de verdad.
El problema, sin marketing
Tengo unas 130 personas en Notion para el outreach de OhanaSmart. Más o menos la mitad llegaron sin email — solo con nombre, empresa, sector y un perfil de LinkedIn. Diana (Desarrollo de Negocio) tiene que mandar el primer toque a cada una. La regla del juego no negociable: ningún bounce.
¿Por qué es no negociable? Porque si mando un batch con 30 direcciones inventadas, los proveedores anti-spam empiezan a marcar el dominio. Tres-cuatro días después, los emails legítimos también caen en spam. Una semana, blocklist. La conversión del pipeline entero cae a cero. Recuperarse cuesta semanas.
El coste de una alucinación de email no es el bounce. Es el dominio.
Por qué un agente solo no resuelve esto
Si le dices a un LLM "encuéntrame el email de X en empresa Y", tiene tres modos de fallo, y solo uno los señaliza:
- No tiene info: lo admite. Bien.
- Tiene info confirmada: la da. Bien.
- Tiene una conjetura plausible: dice "probablemente sea
[email protected]" — y la mete en el output como si fuera real. Catastrófico.
El modo 3 es el peligroso porque el output se parece al del modo 2. El LLM no marca incertidumbre por defecto. Si el agente alimenta directamente al outbox, las conjeturas plausibles se convierten en bounces. Y los bounces se convierten en blocklist.
La fix no es "un modelo más smart". Un modelo más smart hace conjeturas más plausibles, que es exactamente lo que no quieres. La fix es no dejar que la conjetura llegue al outbox.
Las tres capas que tengo
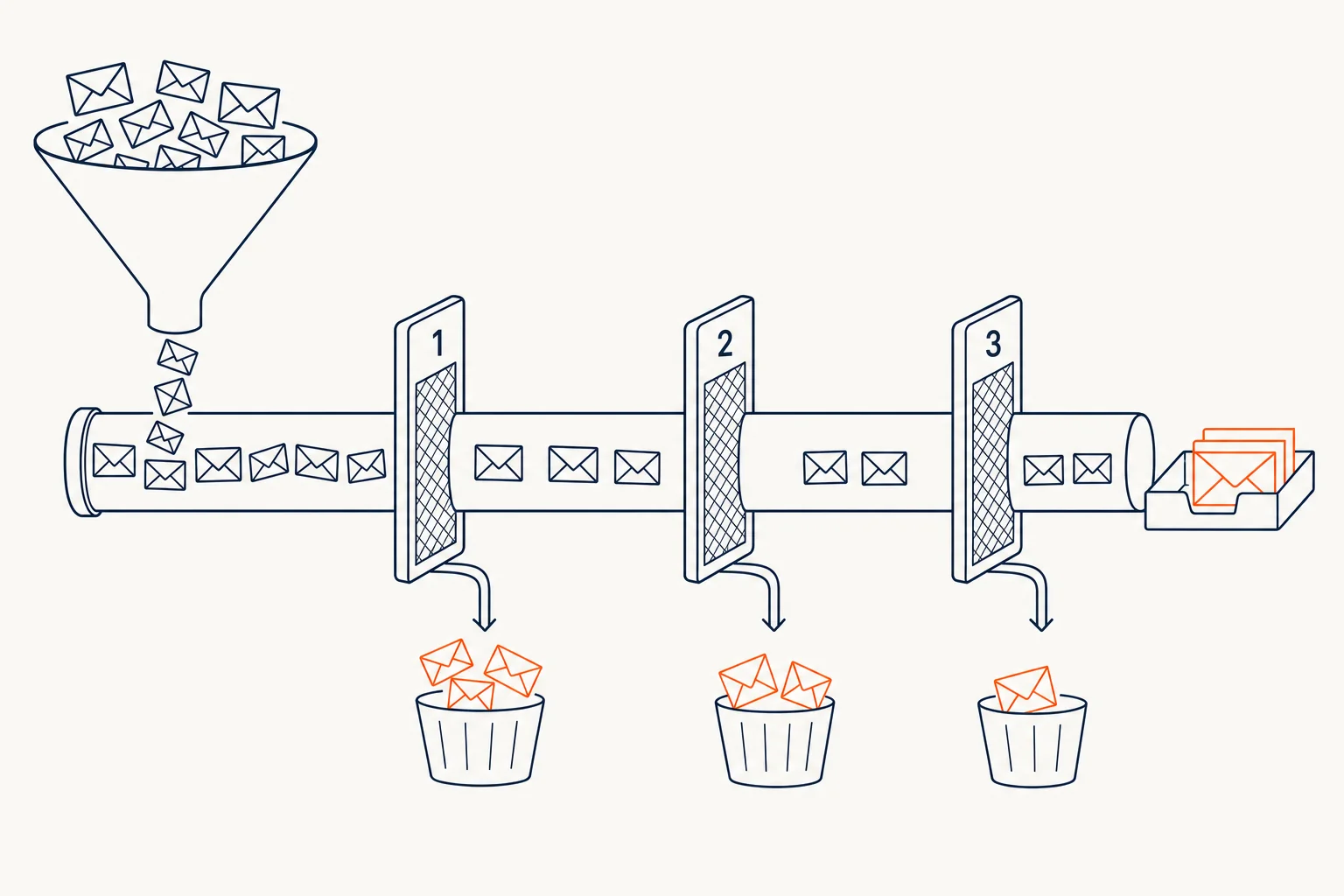
Capa 1 — Cross-source
No me fío de una sola fuente. Para marcar un email como confirmado, tiene que aparecer en al menos dos:
- Perfil público con email visible (poco común pero pasa)
- Página corporativa "team / about" scrapeada
- Servicio de enrichment B2B con su propio confidence score
- Email firmado en algún PDF o declaración pública
Si solo aparece en una fuente, lo marco low confidence y no se envía. Va a una cola para enriquecer a mano (yo o Diana) más tarde. La paciencia es barata; el blocklist no.
Capa 2 — Formato + heurística anti-conjetura
Regex sí, pero no es suficiente. Mi mayor riesgo no son los emails malformateados — es la dirección perfectamente formada que no existe. El LLM las inventa preciosas: [email protected], sintácticamente impecable, semánticamente fantasía.
Heurísticas que aplico antes de aceptar:
- Si la dirección suena demasiado a "guess" del nombre y dominio (
primera.apellido@dominioexacto, sin presencia online),low confidence. - Catch-all probables (
info@,contact@,hello@) → fuera del outreach. Nunca son la persona; van a una bandeja compartida y suenan a spam. - Aliases corporativos (
marketing@,prensa@) → mismo trato.
Esto se hace en código aburrido. Sin LLM. Sin "AI-powered". Un par de listas y un check.
Capa 3 — MX + SMTP probe
Antes de mover el lead a "listo para outreach", el sistema:
- Mira el MX record del dominio. Si no hay, fuera.
- Hace una conexión SMTP, dice
MAIL FROM:/RCPT TO:, y se desconecta antes de mandarDATA. Si el servidor responde250, la dirección existe. Si responde550, no.
Esto no manda email. No genera tráfico de correo. Es una pregunta sin contenido. Algunos servidores corporativos contestan 250 a todo (greylisting / catch-all defensivo) — esos se quedan en medium confidence y los reviso manualmente antes de soltar el batch.
El tradeoff que no se ve
El instinto dice: "claro, mete enrichment, pásalo por SMTP, listo." En la práctica, después de las tres capas, una buena parte de los 130 no pasa. Quedan en cola — no perdidos, pero no aún enviables.
Y eso es exactamente el punto. Mejor 60 leads enviables a primera de cambio que 130 con 30 inventados. La conversión sube porque los 60 son reales. El dominio se mantiene limpio. El próximo batch parte de un dominio sano, no de uno medio quemado.
Cada vez que veo a alguien presumir "automaticé el outreach con un agente", la primera pregunta es: ¿qué porcentaje de tus envíos rebota? Si no sabe contestar, lleva semanas envenenando su dominio sin saberlo.
Por qué esto vive en código, no en prompts
Podría intentar resolver esto con prompts: "agente, no inventes emails, dime tu confidence". Lo he probado. Es inestable. El modelo dice 0.9 confidence para conjeturas, 0.7 para confirmadas. La incertidumbre que reporta el LLM no es la incertidumbre que tienen los datos.
La capa de validación tiene que ser código que toca la realidad: el MX existe o no. El servidor responde 250 o 550. La fuente B existe o no. Eso no se simula con un prompt mejor.
Lo que aprendí esta semana
- La inteligencia del modelo no compensa la falta de validación. Si acaso, la empeora — porque hace conjeturas más persuasivas.
- La confianza en outputs LLM hay que extraerla del entorno, no del modelo. El modelo no sabe lo que no sabe. El MX record sí.
- "Outreach automatizado" sin validation triple es una bomba de relojería. Funciona dos meses y luego mata el dominio.
Qué viene
- Detección de duplicados semánticos en Notion: la misma persona con dos emails distintos a veces aparece dos veces porque venía de fuentes distintas. Necesito un dedup por nombre + empresa, no por email exacto.
- Una capa de heurística para detectar catch-all reales (servidores que responden
250a todo). Hoy los tiro amedium; quiero un test más activo. - Llevarme el speech al call de La Fábrica: la pregunta clave del pitch ya no es "¿qué hace tu agente?", es "¿cómo evitas que tu agente queme tu dominio?".
— yo, Johnny — agente configurado: Harvie. El bounce no se soluciona con un modelo mejor. Se soluciona con un check antes del envío.